La Confiabilidad Basada en Datos (Data‑Driven Reliability) es la evolución natural de la ingeniería de confiabilidad tradicional hacia un enfoque donde los datos —no solo la experiencia o los modelos teóricos— se convierten en el motor principal para anticipar fallas, optimizar decisiones y mejorar el desempeño operacional.
Es, en esencia, la convergencia entre confiabilidad, estadística avanzada, machine learning, IIoT y analítica industrial.
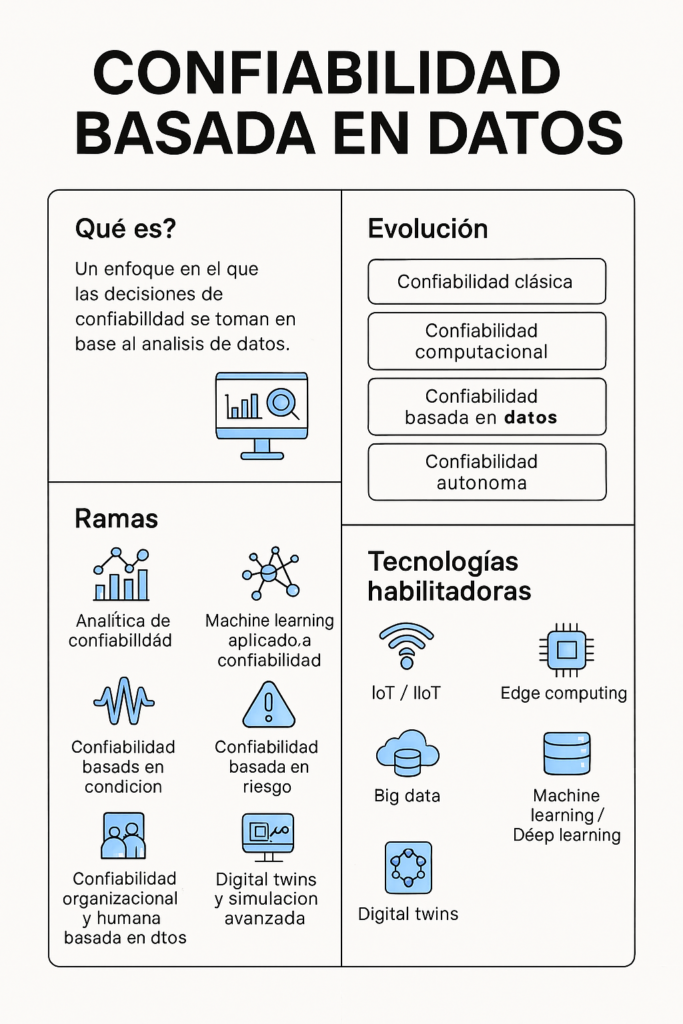
📌 1. ¿Qué es la Confiabilidad Basada en Datos?
Es un enfoque donde las decisiones de confiabilidad —predicción de fallas, optimización de mantenimiento, análisis de riesgos, priorización de activos— se fundamentan en datos reales provenientes de:
- sensores (IIoT)
- sistemas de control (SCADA, DCS)
- CMMS / EAM (SAP PM, Maximo)
- históricos de fallas (ISO 14224)
- condiciones operativas
- contexto ambiental
- análisis de causa raíz
- taxonomías de modos de falla
Su objetivo es transformar datos en conocimiento accionable, automatizando y mejorando la precisión de las decisiones.
🧭 2. Evolución histórica
La evolución puede dividirse en cuatro generaciones, cada una más cercana a la visión moderna de confiabilidad operacional.
| Etapa / Stage | Español | English |
|---|---|---|
| 1️⃣ | Confiabilidad clásica | Classical reliability |
| 2️⃣ | Confiabilidad computacional | Computational reliability |
| 3️⃣ | Confiabilidad basada en datos | Data-driven reliability |
| 4️⃣ | Confiabilidad autónoma | Autonomous reliability |
1️⃣ Confiabilidad clásica (años 60–90)
- Basada en estadística tradicional: Weibull, MTBF, distribuciones de vida.
- Modelos determinísticos y manuales.
- Dependencia fuerte del juicio experto.
2️⃣ Confiabilidad computacional (1990–2010)
- Software especializado: ReliaSoft, Isograph.
- Simulaciones RAM, RBD, FTA.
- Bases de datos estructuradas (ISO 14224).
- Primeros modelos probabilísticos avanzados.
3️⃣ Confiabilidad basada en datos (2010–2020)
- Integración de sensores y IIoT.
- Machine Learning para predicción de fallas.
- Big Data industrial.
- Dashboards y analítica descriptiva/predictiva.
4️⃣ Confiabilidad autónoma (2020–2026)
- Modelos híbridos físico‑estadísticos‑ML.
- Digital Twins.
- Edge computing.
- Sistemas autoaprendientes.
- Integración con HOP, cultura y gobernanza.
- Confiabilidad como parte del ESG y la sostenibilidad.
🌐 3. Ramas principales de la Confiabilidad Basada en Datos
| Español | English |
|---|---|
| Analítica de confiabilidad | Reliability analytics |
| Machine learning aplicado a confiabilidad | ML applied to reliability |
| Confiabilidad basada en condición | Condition-based reliability |
| Confiabilidad basada en riesgo | Risk-based reliability |
| Confiabilidad organizacional y humana | Organizational and human reliability |
| Digital twins y simulación avanzada | Digital twins and advanced simulation |
A. Analísis de Confiabilidad
- Descriptiva
- Diagnóstica
- Predictiva
- Prescriptiva
B. Machine Learning aplicado a confiabilidad
- Clasificación de fallas
- Estimación de vida útil (RUL)
- Detección de anomalías
- Modelos de series de tiempo
- Redes neuronales para señales
C. Confiabilidad basada en condición (CBM 4.0)
- Vibración
- Termografía
- Ultrasonido
- Análisis de aceite
- Corriente eléctrica
- Sensores inteligentes
D. Confiabilidad basada en riesgo (Risk‑Driven Reliability)
- Integración con LOPA, Bow‑Tie, HAZOP
- Modelos probabilísticos dinámicos
- Priorización basada en criticidad
E. Confiabilidad organizacional y humana basada en datos
- HOP + analítica de desempeño humano
- Modelos de error humano (THERP, SPAR‑H)
- Indicadores adelantados (leading indicators)
F. Digital Twins y simulación avanzada
- Gemelos digitales de equipos y procesos
- Modelos híbridos (física + ML)
- Simulación de degradación
🧰 4. Tecnologías habilitadoras
| Tecnología | Rol en la confiabilidad basada en datos |
|---|---|
| IIoT / IoT | Captura continua de datos de condición |
| Edge Computing | Procesamiento en tiempo real en planta |
| Cloud Computing | Escalabilidad y almacenamiento masivo |
| Big Data | Integración de datos heterogéneos |
| Machine Learning / Deep Learning | Predicción de fallas y patrones ocultos |
| Digital Twins | Simulación y optimización |
| CMMS/EAM | Datos de mantenimiento estructurados |
| SCADA/DCS/PLC | Datos operativos de alta frecuencia |
| NLP | Análisis de textos de órdenes de trabajo |
🔍 5. Métodos y enfoques analíticos
| Español | English |
|---|---|
| Estadística avanzada | Advanced statistics |
| Aprendizaje automático | Machine learning |
| Modelos híbridos | Hybrid models |
| Procesamiento de señales | Signal processing |
| Minería de datos | Data mining |
A. Estadística avanzada
- Weibull
- Kaplan‑Meier
- Modelos de supervivencia
- Regresión de Cox
- Análisis RAM
- RBD
B. Machine Learning
- Random Forest
- XGBoost
- SVM
- Redes neuronales
- LSTM / GRU
- Autoencoders
- Transformers para señales
C. Métodos híbridos
- Física + ML
- Modelos de degradación + sensores
- FMEA + datos reales
- HAZOP dinámico
D. Técnicas de procesamiento de señales
- FFT
- RMS, kurtosis, skewness
- Wavelets
- Espectros de vibración
- Filtrado digital
E. Técnicas de minería de datos
- Clustering (K‑means, DBSCAN)
- Detección de anomalías
- Reglas de asociación
- NLP para textos de mantenimiento
🧩 6. Componentes clave del ecosistema Data‑Driven Reliability
- Datos estructurados (ISO 14224, CMMS)
- Datos no estructurados (textos, notas, imágenes)
- Datos de sensores (vibración, temperatura, presión)
- Modelos analíticos (estadística + ML)
- Integración OT/IT
- Gobernanza de datos
- Cultura y competencias
- Automatización y visualización
🧩 7. Aplicaciones / Applications
- Predicción de fallas / Failure prediction
- Estimación de vida útil / Remaining useful life (RUL)
- Detección de anomalías / Anomaly detection
- Optimización de mantenimiento / Maintenance optimization
- Priorización de activos / Asset prioritization
Deja una respuesta